
Offline Reinforcement Learning with Munchausen Regularization
Published in NeurIPS 2021 Offline RL Workshop, 2021
Recommended citation: Liu, Hsin-Yu, Bharathan Balaji, Rajesh Gupta, and Dezhi Hong. " Offline Reinforcement Learning with Munchausen Regularization " Offline Reinforcement Learning Workshop at Neural Information Processing Systems, 2021 (NeurIPS 2021). http://mesl.ucsd.edu/pubs/Hsinyu_NeurIPS2021_OfflineRL.pdf
Most temporal differences based (TD-based) Reinforcement Learning (RL) methods focus on replacing the true value of a transiting state by their current estimate of this value. Munchausen-RL (M-RL) proposes the idea of incorporating the current policy to be leveraged to bootstrap RL.
It regularize policies that are: 1. Too far from the previous one. 2. Too far from uniform policy. The concept of 1., penalizing two consecutive policies that are far from each other is also applicable to offline settings. In our work, we add the Munchausen term in the Q-update step to penalize policies that deviate from previous policy too far.
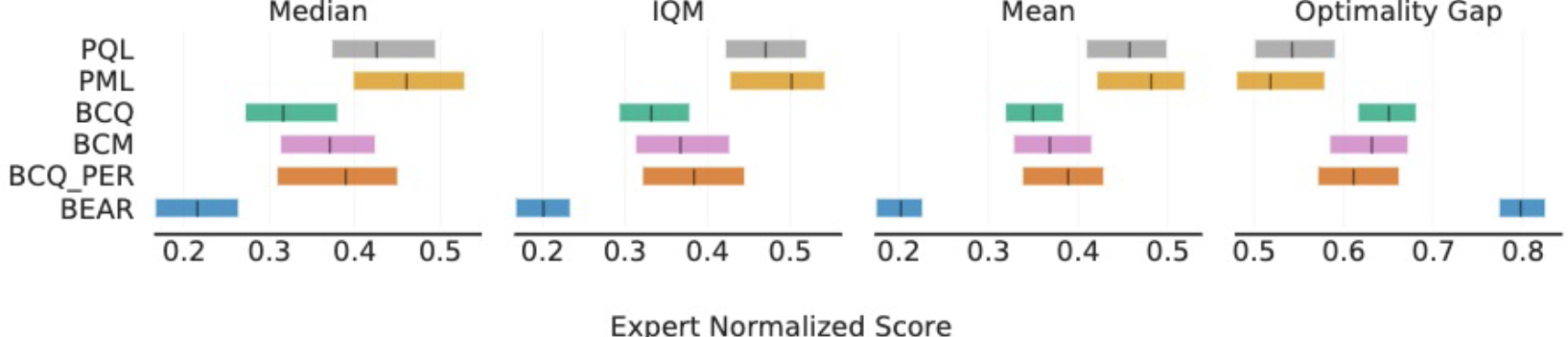
Our results indicate that this method could be implemented in various offline Q-learning methods to help improve the performance. In addition, we evaluate another TD-based method, prioritized experience replay (PER), it prioritizes the mini-batch by its TD-error and weighted importance sampling.
Our results show that Munchausen Offline RL outperforms the original methods that are without the regularization term. The results indicate that adding the extra regularization term indeed helps improve the performance of Q-learning methods even in offline settings.